Claude Opus 4.5 стал лидером в решении задач программирования
Модель искусственного интеллекта Claude Opus 4.5 официально заняла первое место в решении специализированных задач по программированию, продемонстрировав превосходные результаты в независимом тестировании.
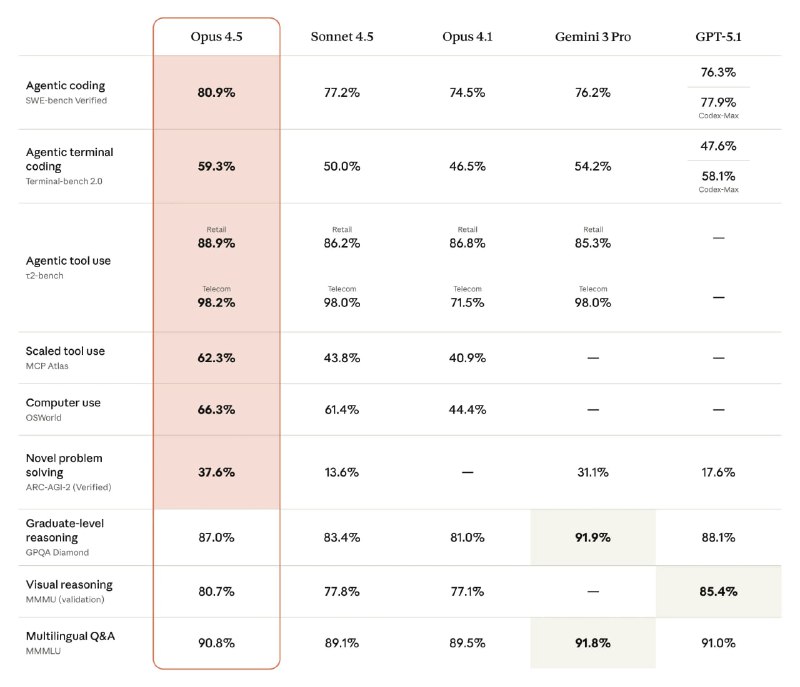
Согласно последним данным, система показала результат 80% на тесте SWE-Bench, что превышает показатели основных конкурентов. Модель Gemini 3 Pro набрала 76%, а GPT-5.1 Codex Max — 78%.
Модели дали настоящую ошибку из GitHub, и она сама всё сделала — разобралась в проблеме, починила баг и выдала готовое рабочее решение
Эксперты отмечают, что ключевым преимуществом Claude Opus 4.5 стала способность полностью автономно анализировать, диагностировать и исправлять реальные программные ошибки, демонстрируя уровень компетенции, приближенный к работе профессиональных разработчиков.